{kind=link}
巧妙!一个传统技术让国产视觉基础模型直接上大分
咱就是说啊,视觉基础模型这块儿,国产 AI 真就是上了个大分——
Glint-MVT,来自格灵深瞳的最新成果。
先来看下成绩——线性探测(LinearProbing):
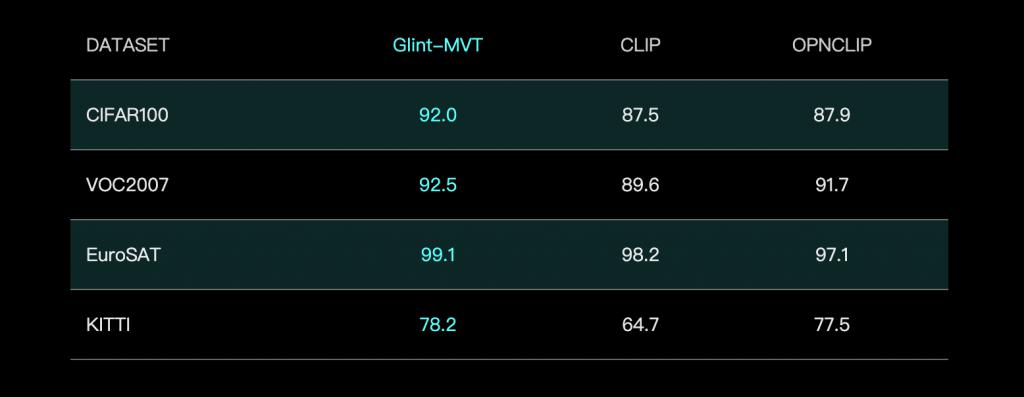
简单来说,线性探测是一种测试预训练模型效果的小技巧,测的就是基本功扎不扎实。它的做法是:
把模型最后一部分换成简单的线性层,其他部分全部保持原样不动;然后只训练这个新加的线性层,通过它的表现来判断模型之前学到的特征好不好用。
这个测试是在 26 个分类测试集中跟 CLIP 和 OpenCLIP 做了对比,结果显示,国产视觉基础模型平均准确率比 OpenCLIP 高 2.3%,比 CLIP 高 1.1%。
再来看应用效果。
如果说视觉基础模型是一个底座,那么它的下游任务,像" 图像理解 + 分割一切 ",便是更为直观的效果展现。
例如下面这张图片,然后我们可以问一下 AI:
你能提供一个分割掩膜给这个图像中触摸篮球的人吗?
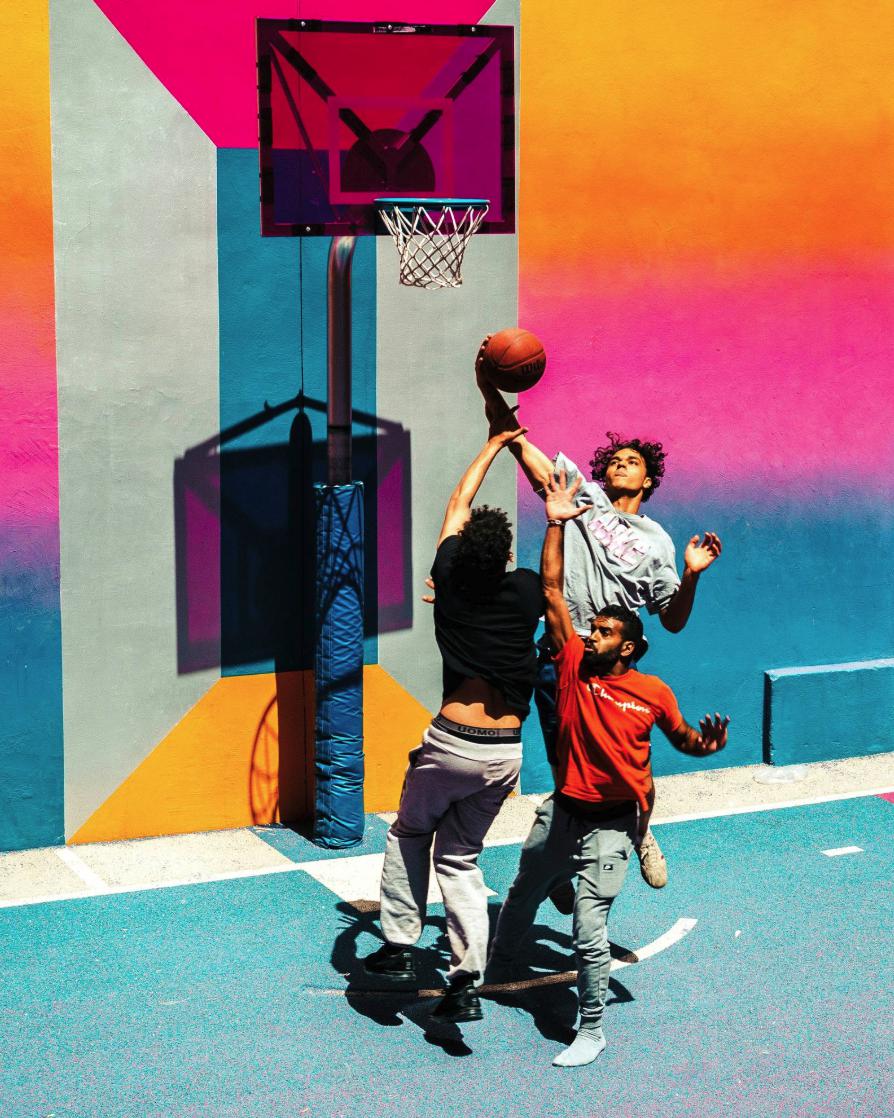
很显然,这个任务的难点在于拿篮球的人被其他人的手、身体等部位挡住,分割难度也大幅增加。
然而,国产 AI 是不在怕的,啪的一下,超精细地把要求的人物给抠了出来:

我们再来看下更加复杂的案例:

面对如此繁杂的图片,不论要求 AI 分割哪种食物,它都能精准无误地识别出来。
Glint-MVT 中的 MVT,全称叫做 Margin-based pretrained Vision Transformer,是团队自研、设计的视觉预训练 Transformer 模型。
它的一大亮点,就是创新性地把原先用于人脸识别的间隔 Softmax(Margin Softmax)损失函数引入了进来,再通过构造百万级虚拟类别训练模型,显著降低数据噪声影响,提升泛化能力。
并且从实测和性能效果上来看,在各种专业下游任务中的表现,要比 CLIP 等其他 ViT 模型的结果更好。
在 Glint-MVT 这个底座之上,团队针对引用表达分割(RES,Referring Expression Segmentation)和图像理解,还分别训练出了多模态模型:Glint-RefSeg 模型和MVT-VLM 模型。
Glint-RefSeg 是无需特别搜集训练就可以分割一切,从刚才的例子中也是感受到其实力,并且相比其他 RES 任务的模型,它取得了当前的SOTA。
至于 MVT-VLM,它在图像理解的实力,可以用下面的例子来展示:
请分别告诉我图中运动员的性别以及衣服颜色和号码。
即使图片中红衣服的号码呈现出刁钻的角度,它也能轻松识别:

那么 Glint-MVT 还有哪些效果,我们继续来看。
视频、具身智能都用上了
首先在分割这件事上,除了图像之外,Glint-RefSeg也是可以用在视频上的。
例如给定一段 Bruno Mars 的唱跳视频,效果是这样的:
可以看到,不论画面、角度如何切换,任务要求的 " 穿粉色西装的男子 ",稳稳地被 AI 锁定住了。
而且即使 Bruno Mars 动作幅度再大、变化再快,也丝毫不影响 AI 分割的效果,尤其是手部等细微之处,可以说是拿捏得相当到位。
而且除了传统场景之外,像具身智能这样的 fashion 场景,Glint-MVT 也是用上了。
例如这样:

在看完机械臂的操作之后,如果问 AI:
把橙子放到白色碗里,(结果是)合适的吗?请回答是或否。
AI 就会根据当前的场景回答:
是。
从种种的效果来看,不得不说 Glint-MVT 这个视觉基础模型,基本功是有够扎实的。
那么接下来的一个问题就是:
怎么做到的?
正如我们刚才提到的,Glint-MVT 技术核心亮点,就是把间隔 Softmax引入了进来。
具体而言,Glint-MVT 采用基于大类别分类的间隔 Softmax 损失函数进行训练,通过引入 " 类别间隔 " 和 " 特征紧凑性 " 的双重约束,解决传统 Softmax 在大规模分类中语义区分不足的问题。
在此基础上,格灵深瞳团队提出了进一步的优化方案。
首先是虚拟类别构造。
团队利用图像文本特征聚类技术,将大规模数据集(如 LAION 400M)划分为 100 万虚拟类别,替代传统人工标注标签,可以高效地提升数据规模。
其次是噪声抑制与计算优化。
团队在训练时仅随机选取部分负类中心(采样比例约 10%),如此一来,就可以降低类别间冲突对模型的干扰,同时减少计算量和显存占用。
相比 CLIP 的实例对比学习,间隔 Softmax 通过显式建模类别间边界,能让模型更聚焦语义结构,在图像检索、分类等任务上表现更优。
以上就是 Glint-MVT 效果提升的关键,而 Glint-RefSeg 和 MVT-VLM 等模型也是基于这个大底座而来。
例如 Glint-RefSeg 采用 MVT v1.1(MLCD)作为核心视觉编码组件,并融合了大语言模型与 SAM 解码器的技术优势。
这一设计使得模型能够理解用户的自然语言描述,并精确识别和分割图像中相应的目标对象,输出高质量的分割掩膜。
并且从结果来看,已然是处于业界 SOTA:

但格灵深瞳团队在技术上的动作还远不止于此。
他们已经将技术锚点锁定到了更复杂的多模态大模型和视频理解方面,而且也即将推出相应的模型:MVT v1.5 和 MVT v2.0(Video)。
视觉领域的精耕者
除了技术上的创新,格灵深瞳之所以能够在视觉基础模型上有如此的突破,团队的发展,也是关键因素之一。
格灵深瞳可以说是国内计算机视觉领域的早期探索者,从 2013 年起便始终专注于视觉技术的研发与落地。
从早期的安防、金融行业解决方案,到如今聚焦视觉大模型与多模态技术,其技术演进始终围绕一个核心:让 AI 真正解决产业痛点。
这次发布的 Glint-MVT 就是对这句话非常好的诠释。
因为它并非单纯追求学术指标,而是通过提升下游任务(如分类、检测、分割)的能力,为实际应用场景赋能。
由此可见,即便进入大模型时代,格灵深瞳依旧没有盲目追逐参数规模和噱头,而是坚持" 从业务需求中来到产品落地中去 "的研发逻辑。
与此同时,格灵深瞳还是一家主动拥抱开源,但拒绝跟风的企业。
它的开放策略目标非常明确,正如CEO 吴一洲强调" 回到初心,能贡献什么就贡献什么 ",通过充分的开放和分享,期待能激发更多社区伙伴的创新,从而形成创新互哺的良性循环,伙伴越聚越多,技术越玩越强。她在公司里也鼓励团队 " 勇敢点 "、" 浪一点 "。 她认为当下技术迭代快,但也更加进入了深水区,要更加拥有直面技术和应用本质的勇气。
再如格灵深瞳算法研究院院长冯子勇,在 2016 年博士毕业之后,便加入格灵深瞳。
他带领的格灵深瞳灵感实验室,聚焦于视觉及相关模态特征表达与应用。主要研究方向有视觉基础大模型、多模态大模型、图文多模态表征、大规模分布式训练等。
冯子勇主导了多项关键算法的技术攻关,特别在 " 人脸识别与聚类算法技术 " 以及 " 视频解析算法技术 " 等专业领域取得了显著成就。
例如在银行场景中,实现了倒地检测在上万路摄像头下实际使用,获得客户高度认可。相关技术在国际赛事中表现优异,还斩获了 OpenFAD2023 人体动作识别竞赛和首届 SkatingVerse 花样滑冰动作识别竞赛双料冠军。
他所带来的年轻化思维与丰富实践经验显得格外宝贵。
而在格灵深瞳的身上,我们或许还能看到大模型时代发展的一个缩影——
既需要头部玩家,也离不开格灵深瞳这样的精耕者。
格灵深瞳坚持从场景中提炼技术、以开源回报生态的路径,或许正是 AI 落地 " 最后一公里 " 的关键解法。
AI 技术已从通用探索进入垂直深耕阶段,不同企业需要像 " 打仗 " 一样各司其职,找准自己的军种角色,比盲目扩张更重要;格灵深瞳更像是 " 特种兵 ",通过视觉基础模型为下游任务提供训练支持。
这种务实与开放并存的哲学,或许正是格灵深瞳在视觉长跑中持续领跑的密码。
Glint-MVT 体验地址:
https://glint-mvt.com
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
点亮星标
科技前沿进展每日见